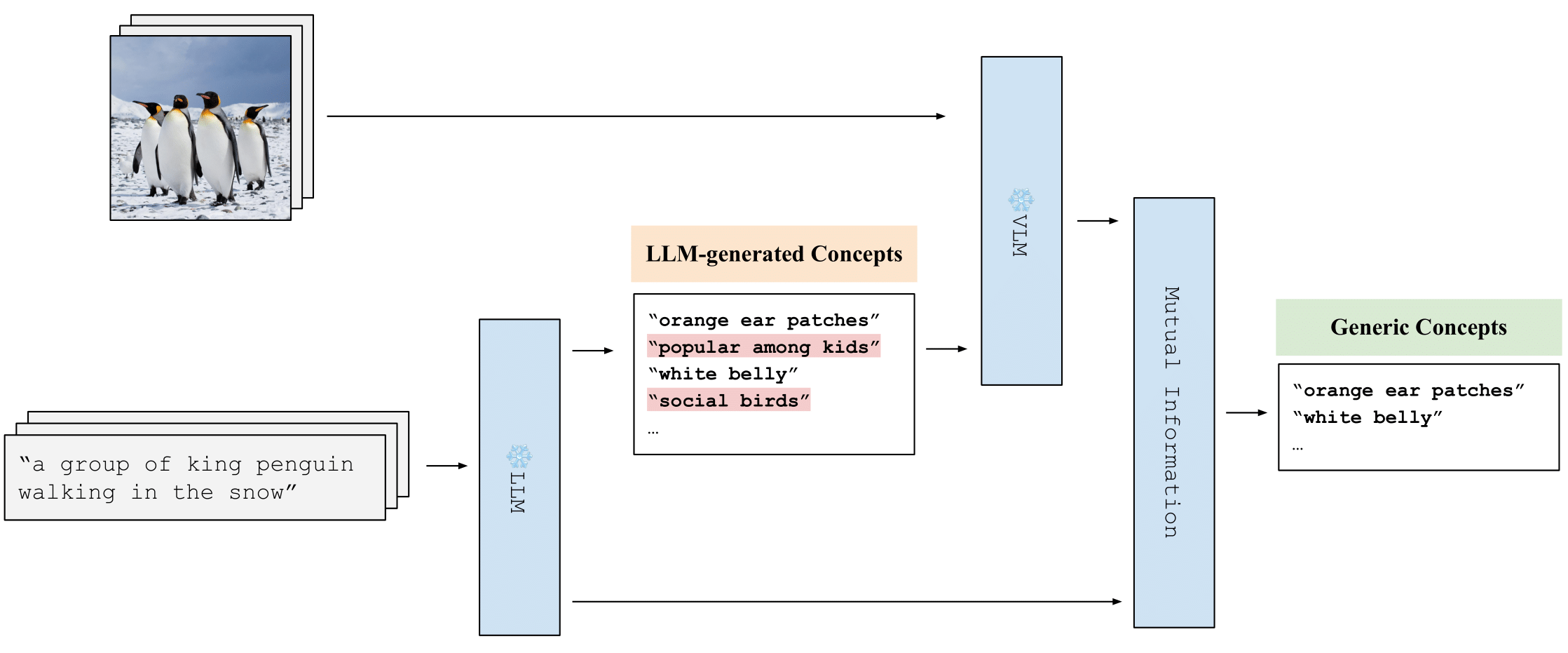
Multimodal Concept Discovery enables researchers and engineers to uncover shared concepts across diverse data streams such as text, images, audio, and beyond. By aligning these modalities into a cohesive representation, this field unlocks cross-modal insights that power more robust, interpretable, and transferable AI systems.
Key Points
- Cross-modal alignment creates a unified concept space where ideas expressed in different signals map to the same latent representations.
- Contrastive and multi-task learning strategies help discover concepts with minimal supervision while preserving modality-specific nuances.
- Interpretable concept axes emerge when discovered concepts align with human-understandable attributes across modalities.
- Diverse data, robust evaluation, and fair sampling are essential to ensure cross-modal concepts generalize well.
- Applications span multimedia search, cross-modal retrieval, and domain-specific tasks like medical analytics and robotics.
Architectural Foundations
At its core, Multimodal Concept Discovery relies on shared latent spaces that bridge modality-specific encoders. A typical architecture combines modality-specific encoders with a shared concept space where corresponding signals are aligned via alignment losses or joint objectives. This setup enables the model to reason about concepts such as “object,” “scene,” or “sound” in a way that remains consistent across text, image, and audio inputs.
Techniques and Approaches
Several techniques drive cross-modal concept discovery. Contrastive learning aligns representations by pulling related multimodal pairs closer and pushing unrelated pairs apart. Cross-attention mechanisms let one modality inform another, revealing how concepts manifest differently across signals. Canonical correlation analysis and its neural variants help identify shared variance between modalities, while graph-based methods model relational structure among concepts to preserve semantic topology.
Applications and Impact
Real-world impact comes from enabling more effective search, recommendation, and automated understanding of multimedia content. In media analytics, cross-modal concept discovery improves tagging and retrieval by recognizing the same concept across captions, visuals, and audio. In healthcare, aligning radiology reports with imaging data can reveal clinically meaningful concepts that support faster diagnosis and better patient outcomes.
Evaluation and Metrics
Evaluating cross-modal concept discovery requires benchmarks that reflect real tasks. Common metrics include retrieval accuracy across modalities, concept purity and coherence in the latent space, and downstream task performance such as classification or ranking under cross-modal conditions. Additionally, fairness and robustness tests help ensure that discovered concepts do not encode biased or fragile patterns that break with distribution shifts.
Challenges and Best Practices
Key challenges include data heterogeneity, alignment noise, and the need for scalable evaluation. Best practices involve curating diverse, well-annotated multimodal datasets, employing rigorous ablations to isolate the contribution of each modality, and validating findings with human-in-the-loop assessments when possible. Transparency in the discovered concepts—what they represent and where they fail—also supports responsible deployment.
How does Multimodal Concept Discovery differ from uni-modal concept learning?
+Uni-modal concept learning derives representations from a single signal type, while Multimodal Concept Discovery explicitly seeks shared concepts that manifest across multiple modalities. The cross-modal perspective uncovers relationships that are invisible when focusing on one modality alone and enables models to reason about concepts that are coherently expressed in text, visuals, and audio.
What datasets best support cross-modal concept discovery in practice?
+Datasets that pair aligned modalities—such as image-caption pairs with audio annotations or video with transcripts—offer rich signals for discovering shared concepts. Examples include multimedia datasets with comprehensive cross-modal annotations, as well as synthetic datasets where multimodal alignment can be controlled and analyzed. The key is to ensure the data covers diverse contexts and distributions to avoid overfitting to a narrow modality pairing.
What are practical evaluation strategies for cross-modal concept discovery?
+Practical evaluation combines intrinsic and extrinsic tests. Intrinsic measures examine the coherence of the latent cross-modal space (e.g., how well related concepts cluster together), while extrinsic tests assess performance on downstream tasks like cross-modal retrieval or classification. Human-in-the-loop reviews of discovered concepts can validate interpretability, and controlled ablations help identify modality-specific contributions to the concept structure.
Can Multimodal Concept Discovery improve zero-shot generalization?
+Yes. By learning concepts that are shared across modalities, models gain access to complementary signals for recognizing unseen combinations. When a concept is grounded in both textual and visual or auditory cues, the model can apply that concept to novel instances without requiring task-specific labeled examples, enabling more robust zero-shot generalization.

